


Wyszukiwarka PELCRA dla danych NKJP
Zerknij też na najnowsze informacje o wyszukiwarceTematy pomocy
1. O wyszukiwarce2. Zawartość korpusu
3. Skrócone odsyłacze
4. Składnia zapytań w przykładach
5. Sortowanie
6. Grupowanie
7. Metadane
8. Wyrazy kontekstowe
9. Podkorpus zrównoważony
10. Analiza rejestru
11. Szeregi czasowe
12. Pobieranie wyników postaci arkuszy kalkulacyjnych
13. Wyszukiwanie kolokacji
14. Wyszukiwarka dla danych mówionych
15. Dostęp programistyczny
16. Cytowanie
O wyszukiwarce
Wyszukiwarka PELCRA dla danych NKJP jest opracowywana przez grupę PELCRA w Instytucie Anglistyki Uniwersytetu Łódzkiego. Narzędzie to umożliwia szybkie i wygodne przeszukiwanie zasobów zgromadzonych na potrzeby Narodowego Korpusu Języka Polskiego. Wyszukiwarka jest oparta na składni zapytań korpusowych, która z jednej strony oferuje funkcjonalność porównywalną z opcjami wyszukiwania dostępnymi w innych narzędziach korpusowych, a z drugiej umożliwia szczególnie skuteczne wyszukiwanie pojedynczych wyrazów, wariantów morfologicznych i semantycznych oraz elastycznych wielowyrazowych kolokacji w bardzo dużych korpusach.Zawartość korpusu
Wyszukiwarka PELCRA NKJP umożliwia przeszukiwanie zrównoważonej wersji korpusu (ok. 300 milionów segmentów)oraz całej puli danych NKJP (ok. 1500 milionów słów tekstowych, czyli ok. 1800 milionów segmentów) zebranych w ramach projektu.Skrócone odsyłacze
Zanim przejdziemy do omawiania poszczególnych funkcji wyszukiwarki, warto wprowadzić opcję generowania skompresowanych odsyłaczy do wyników. Aby ułatwić użytownikom odtwarzanie wyników wysyłanych do wyszukiwarki zapytań można za pomocą przycisku URL stworzyć krótki odsyłacz do bieżącego ekranu zapytania. Odsyłacz zostaje wyświetlony tuż pod oknem wyszukiwania, np.: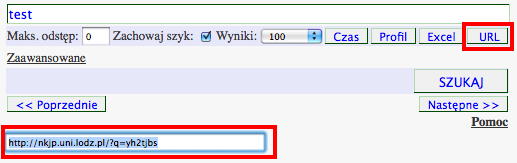
W skompresowanym odsyłaczu zakodowane są wszystkie informacje o wybranych opcjach wyszukiwania. Po jego kliknięciu wyświetlany zostanie nie tylko ekran zapytania, ale też wyniki, które zwraca dane zapytanie. Taki skompresowany odsyłacz można łatwo zapisać, zamieścić w publikacji, lub przesłać pocztą elektroniczną.
Przy większości przykładów omawianych poniżej podajemy bezpośredni skrócony odsyłacz do ekranu wyników pasujących do danego zapytania.
Składnia zapytań w przykładach
Wyszukiwanie dokładnych dopasowań pojedynczych wyrazów - tymianek
Aby wyszukać wystąpienia danego słowa w korpusie, należy je wpisać w podłużnym polu tekstowym na górze formularza zapytania. Po kliknięciu przycisku Szukaj wyświetlą się wystąpienia tego słowa w zindeksowanym korpusie. Na przykład po wpisaniu wyrazu tymianek powinny się ukazać konteksty zawierające jego dokładne dopasowania:Bezpośredni odsyłacz
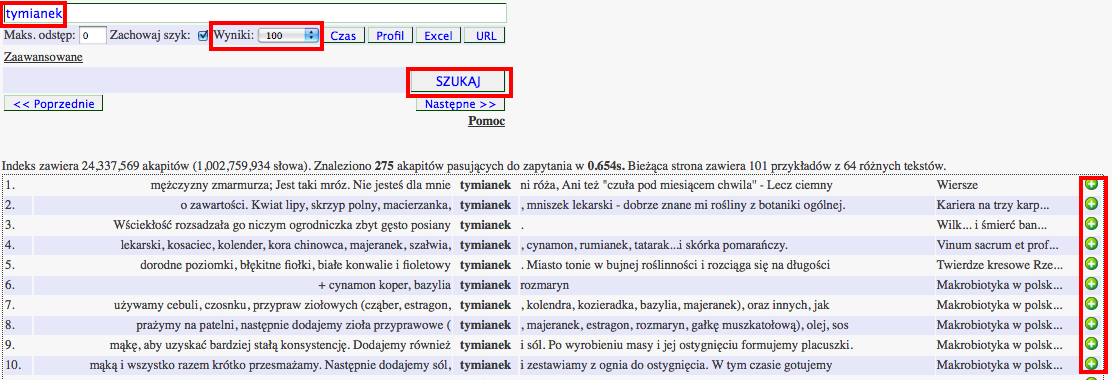
Ogólna liczba kontekstów pasujących do zapytania jest podawana bezpośrednio nad tabelą wyników. Wyniki można posortować według dopasowania (ma to sens w przypadkach opisywanych poniżej), lub też według lewego albo prawego słowa w konkordancji. Możliwe jest też określenie maksymalnej liczby wyników pojawiających się na stronie. Przechodzenie między kolejnymi stronami wyników umożliwiają przyciski << Poprzednie oraz Następne >>. Informacje o tekście, z którego pochodzi dany cytat, a także szerszy kontekst wystąpienia można uzyskać poprzez kliknięcie symbolu zielonego plusa w ostatniej kolumnie danego wiersza wyników.
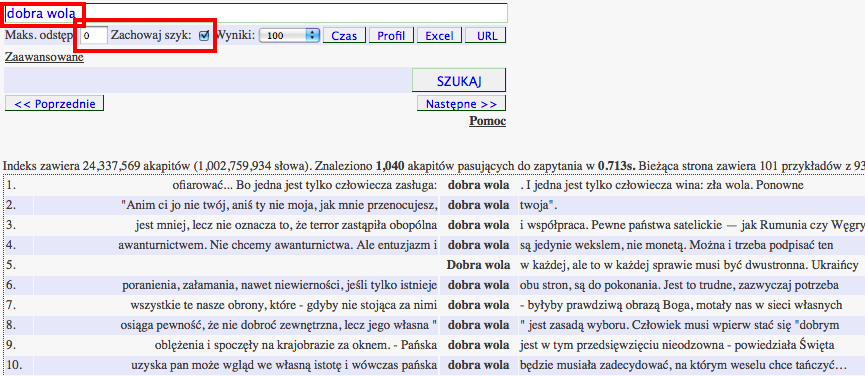
Wyszukiwanie dokładnych dopasowań fraz - dobra wola
Aby wyszukać frazę dokładnie pasującą do zapytania, należy ją wpisać w polu zapytania, oraz zaznaczyć opcję Zachowaj szyk oraz określić maksymalny odstęp między wyrazami wartością 0:Bezpośredni odsyłacz
Ortograficzne symbole wieloznaczne - tymian*
Składnia obsługuje kilka rodzajów symboli wieloznacznych. Dwa podstawowe symbole wieloznaczne, tj. '*' (0 lub więcej dowolnych znaków) oraz '?' (jeden dowolny znak) umożliwiają ortograficzne rozszerzenie terminu zapytania. Na przykład zapytanie tymian* zwraca dopasowania tymianek, tymiankowy, ale też Tymiankach. Z kolei zapytanie osobliw? zwraca dopasowania wyrazów osobliwy, osobliwa, osobliwą, itd.tymian* - bezpośredni odsyłacz
Wyszukiwanie fleksyjne słownikowe - tymianek**
W językach bogatych fleksyjnie ortograficznie rozszerzone zapytanie może zwracać mało dokładne konkordancje, w których warianty fleksyjne są przemieszane z derywatami należącymi do innej kategorii części mowy.Dlatego w wyszukiwarkach tworzonych dla korpusów polszczyzny bardzo przydatna jest możliwość wyszukiwania fleksyjnego. Opisywana tu wyszukiwarka obsługuje na razie prosty, ale bardzo przydatny rodzaj wyszukiwania fleksyjnego, tzn. wyszukiwanie fleksyjne słownikowe (na podstawie słownika Morfologik). Aby automatycznie rozszerzyć zapytanie o warianty fleksyjne zadanej formy podstawowej (np. rzeczownika w mianowniku, rodzaju męskim w liczbie pojedynczej), należy na końcu takiej formy dodać dwa symbole gwiazdki '**'. Na przykład zapytanie tymianek** może zwrócić następujący zbiór dopasowań:
tymianek** - bezpośredni odsyłacz
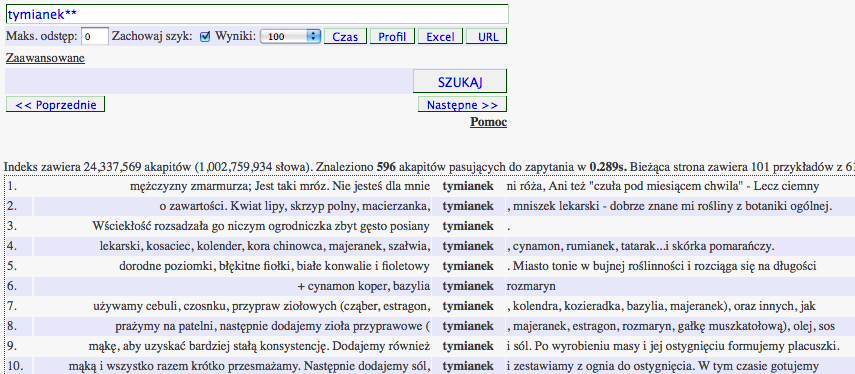

Warto zaznaczyć, że chwilowo omawiana wyszukiwarka obsługuje tylko wyszukiwanie fleksyjne na podstawie słownika fleksyjnego Morfologik (stąd w wynikach dla zapytania podanego powyżej może się pojawić nazwa miejscowości "Tymianka").
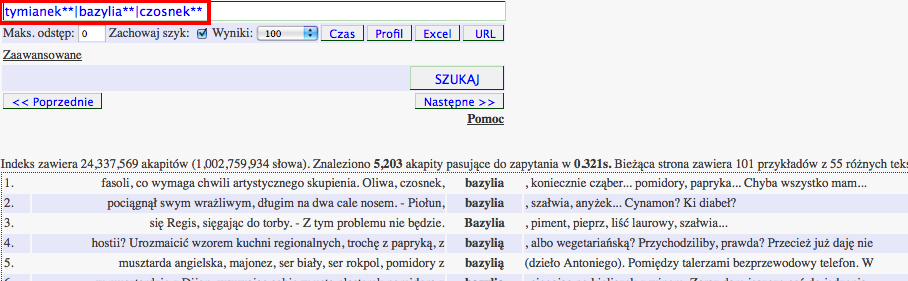
Wyszukiwanie wariantów - tymianek**|bazylia**|czosnek**
Składnia wyszukiwarki umożliwia również formułowanie zapytań zawierających warianty morfologiczne, zbiory synonimów lub nawet antonimy określane przez autora zapytania. Użycie symbolu '|' spowoduje, że dopasowane zostaną wystąpienia dowolnego z wyrazów w danej grupie wariantów. Na przykład zapytanie tymianek**|bazylia**|czosnek** zwróci wystąpienia dowolnego z tych trzech wyrazów (w tym wypadku dopasowane zostaną również ich odmiany, ze względu na użyty symbol podwójnej gwiazdki):tymianek**|bazylia**|czosnek** - bezpośredni odsyłacz

Rozszerzenie ortograficzne na początku wyrazu - *essa**
Wyszukiwarka obsługuje również zapytania z "gwiazdką" na początku wyrazu. Na przykład zapytanie *filetow* zwróci wystąpienia wyrazów sfiletować, odfiletować, oraz wyfiletować. Z kolei zapytanie *essa** zwróci wszystkie odmiany występujących w słowniku morfologicznym wyrazów zakończonych przyrostkiem -essa, czyli na przykład stewardessa, poetessa, hostessa.Dopasowywanie elastycznych związków frazeologicznych poprzez wyszukiwanie kontekstowe - łza**|łezka**___oko**
Składnia wyszukiwarki umożliwia szczególnie wygodne wyszukiwanie wielowyrazowych związków frazeologicznych, które często cechują się luźnym szykiem wyrazów. Aby wyszukać kolokacje rzeczowników łza oraz/lub łezka z rzeczownikami oko w zadanym kontekście we wszystkich odmianach tych wyrazów, należy sformułować zapytanie łza**|łezka**___oko** (grupy wariantów są tu rozdzielone potrójnym podkreślnikiem) Maksymalny odstęp między terminami zapytania możemy dla przykładu określić wartością 2, przy czym zaznaczenie opcji Zachowaj szyk ograniczy liczbę dopasowań do kontekstów, w których wyrazy występują w kolejności ich podania w zapytaniu.Podobne, choć nieco bardziej uściślone zapytanie łza**|łezka**___oko**___kręcić**|zakręcić** może zwrócić następujący zbiór wyników:
łza**|łezka**___oko**___kręcić**|zakręcić** - bezpośredni odsyłacz
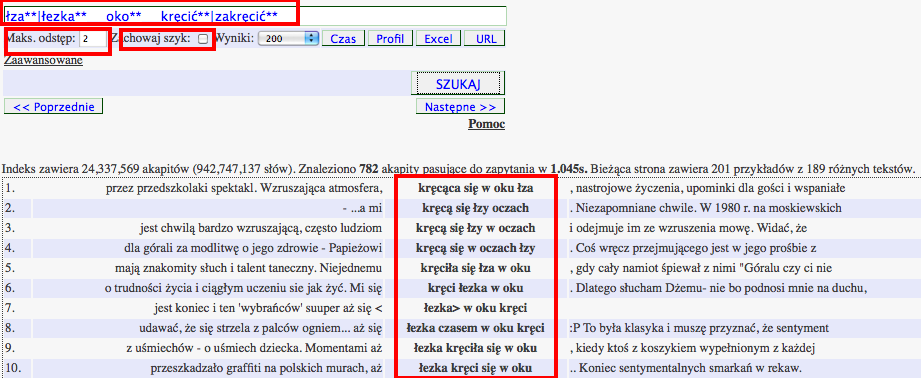
Warto zwrócić uwagę na fakt, iż w wielu innych wyszukiwarkach korpusowych dopasowanie tak elastycznego związku frazeologicznego wymagałoby sformułowania co najmniej kilku osobnych zapytań dla poszczególnych wariantów.
Sortowanie
Opcje sortowania oraz grupowania wyników dostępne są w Zaawansowanym formularzu wyszukiwania.Zbiory wyników można sortować dwustopniowo według następujących kryteriów:
a) Dopasowanie (środek). Sortowanie według dopasowania ułatwia analizę konkordancji wariantów ortograficznych i morfologicznych. Na przykład posortowanie wyników zapytania ręka** według dopasowania podzieli konkordancje na podzbiory zawierające wystąpienia różnych odmian rzeczownika ręka.
b) Lewy lub prawy kontekst. Sortowanie według kontekstu umożliwia prostą analizę najczęstszych kolokacji pozycyjnych występujących w zbiorze wyników.
c) Źródło. Źródłem w przypadku tekstów gazetowych jest tytuł gazety (ale nie pojedynczego artykułu), a w przypadku książek tytuł książki.
d) Data publikacji.
e) Kanał, np. prasa, książka, internet, nagrania języka mówionego.
Warto podkreślić, że sortowane są tylko zbiory wyników (maks. 5000 na raz), a nie wszystkie wystąpienia dopasowania w korpusie.
Grupowanie
Pewnych problemów przy analizowaniu wyników konkordancji z dużych korpusów nastręczają powtórzenia wystąpień częstych wyrazów w tych samych gazetach, książkach, lub też w tekstach z tego samego okresu. Często użytkownika korpusu interesują przykłady użycia danego wyrazu lub frazy w różnych gazetach, tekstach, latach, podczas gdy zbiory nie pogrupowanych wyników mogą zawierać nadmiar przykładów z jednego źródła.Opcja grupowania wyników umożliwia określenie maksymalnej liczby wyników z danego roku, źródła, lub tekstu. Widać to poniżej na przykładzie zapytania, które z danego źródła zwraca maksymalnie trzy wyniki na jednym ekranie wyników.
Grupowanie - bezpośredni odsyłacz
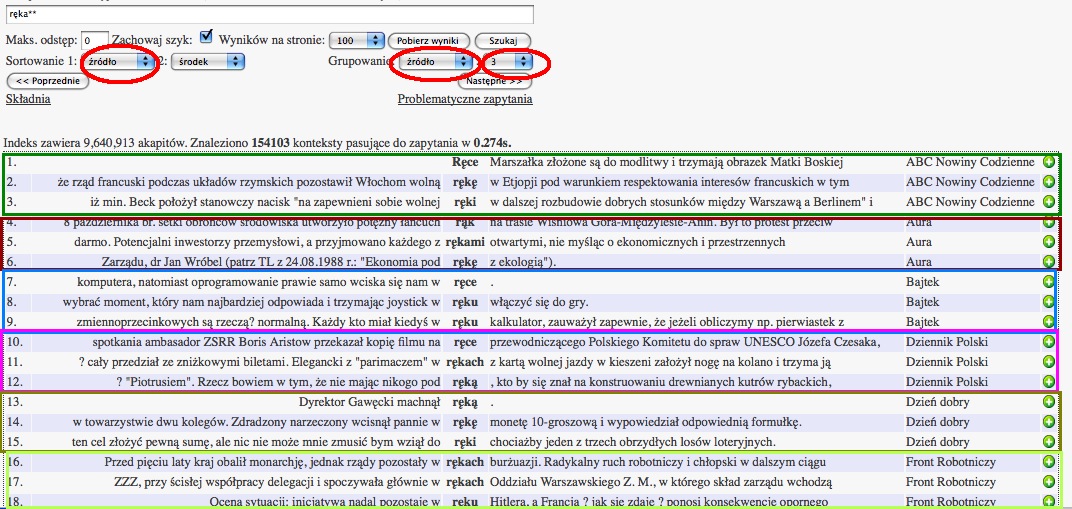
Po wybraniu kryterium grupowania i określeniu maksymalnej liczby wyników, wyświetlone zostają co najwyżej 3 wystąpienia dopasowania w danej gazecie lub książce.
Wyszukiwanie po metadanych
W zaawansowanym formularzu opcji możliwe jest także zawężenie wyszukiwania do wystąpień dopasowań w tekstach o zadanym typie funkcjonalnym, tytule lub też dacie publikacji. Domyślnie w polu metadanych musi wystąpić jedno lub więcej z podanych słów kluczowych, ale poprzedzając słowo kluczowe operatorem AND możemy wymusić jego wystąpienie (przykład).W polach metadanych można także stosować rozszerzenie ortograficzne, oraz dowolnie zagnieżdżać warunki wystąpienia terminów. Na przykład wpisanie w polu Tytuł źródła warunku gazeta AND (Lubuska OR Wrocławska) ograniczy wyszukiwanie do tekstów z Gazety Lubuskiej lub Gazety Wrocławskiej.
Wyrazy kontekstowe
Pewne możliwości ujednoznaczniania wyników zapytania daje opcja określania wyrazów kontekstowych, które mogą, lub nie powinny wystąpić w tym samym akapicie, którym znaleziono dopasowanie zapytania.Przypuśćmy na przykład, że szukamy wystąpień wyrazu połączenie w sensie połączenie telefoniczne i że chcemy automatycznie odsiać wszystkie konkordancje, które zawierają wyraz kolejowy, albo frazę "z Internetem". W tym celu można na przykład wpisać w polu Wymagane wyrazy kontekstowe zapytanie:
zamiejscow* OR telefoniczn*
, a w polu Niedopuszczalne wyrazy kontekstowe zapytanie:
"z Internetem" OR kolejow*
. W zwróconych wynikach powinny się w ten sposób znaleźć głównie wystąpienia rzeczownika połączenie w znaczeniu połączenie telefoniczne.
Podkorpus zrównoważony
Korpus zrównoważony stylistycznie to wybór z tekstów całego korpusu według ustalonych proporcji rejestrów stylistycznych i rodzajowych. Ten korpus ma być reprezentatywny, tzn. proporcje częstości wyrazów i konstrukcji, kolokacje (typowe skojarzenia) oraz inne cechy leksykalne i gramatyczne powinny odpowiadać poczuciu językowemu przeciętnego użytkownika polszczyzny.Oczywiście pełna reprezentatywność korpusu jest tylko ideałem, do którego można jedynie dążyć. Np. udział literatury pięknej w różnych europejskich korpusach narodowych waha się od 3,5 procent w korpusie słoweńskim do 40 procent w korpusie rosyjskim. Aby zbliżyć się do ideału reprezentatywności w polszczyźnie, oparliśmy się na badaniach czytelnictwa w Polsce.
W NKJP przyjęliśmy następującą strukturę zbioru:
- Książki 29%
-
- Literatura piękna 16%
- Literatura faktu 5,5%
- Książki naukowo-dydaktyczne 2%
- Książki i prasa informacyjno-poradnikowe 5,5%
- Prasa 50%
-
- Prasa 50%
- Gazety 26%
- Periodyki 24%
- Inne teksty pisane (urzędowe, listy) 4%
- Internet (blogi, fora, strony www) 7%
- Teksty mówione (konwersacyjne naturalne i medialne, protokoły sejmowe) 10%
Aby ograniczyć wyszukiwanie do podkorpusu zrównoważonego, należy wybrać odpowiednią wartość opcji Podkorpus w ustawieniach zaawansowanych.
Analiza rejestru
Teksty NKJP opatrzone są informacją o typie funkcjonalnym, dzięki czemu możliwe jest sprawdzenie frekwencji występowania danego wyrazu, lub frazy w różnych rejestrach języka. Aby wygenerować wykres słupkowy obrazujący frekwencję danego wyrazu lub frazy, wystarczy kliknąć przycisk Profil po wpisaniu zapytania. Na przykład po wpisaniu zapytania zważywszy na i kliknięciu przycisku Profil:
wygenerowany zostaje mniej więcej taki wykres słupkowy, z którego wynika, że fraza zważywszy na ... pojawia się najczęściej w danych "quasi-mówionych", na przykład w sprawozdaniach stenograficznych Sejmu RP:
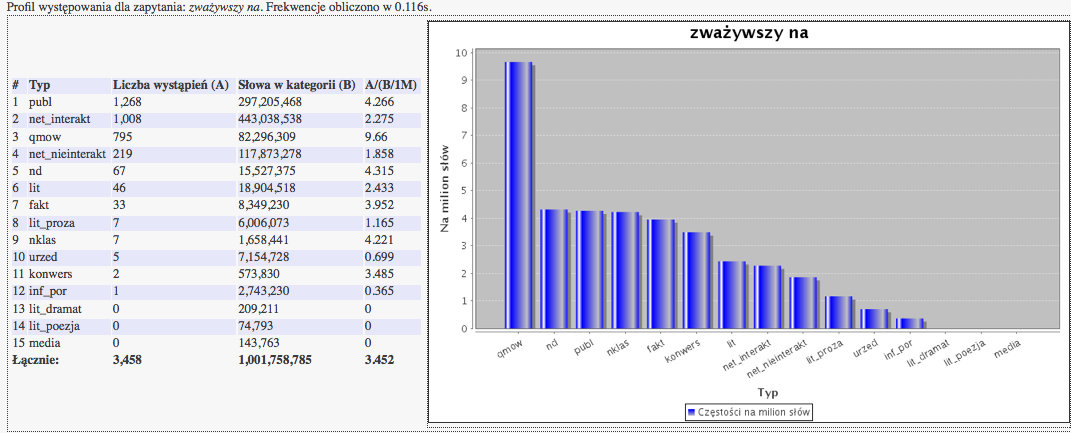
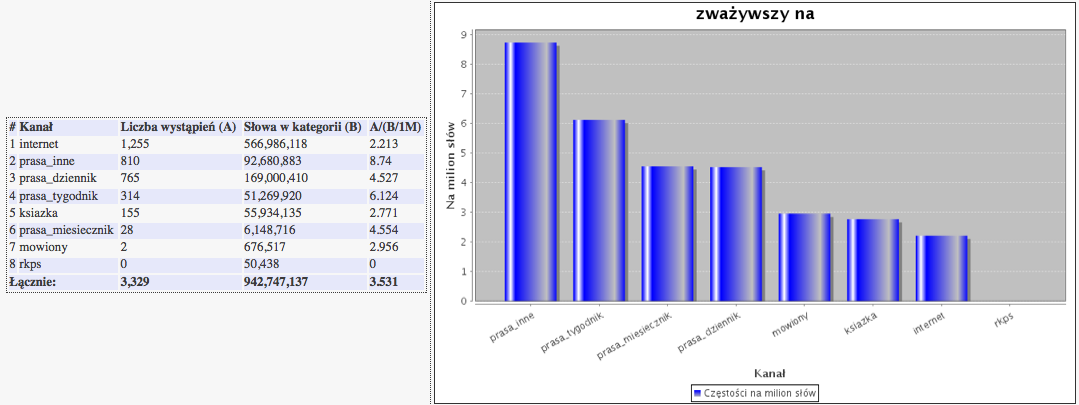
Poniżej wykresu częstości w różnych typach tekstów generowany jest wykres słupkowy częstości danego wyrazu lub frazy w "kanałach" uwzględnionych w taksonomii NKJP.
Poniższa tabela zawiera objaśnienia skrótów typów funkcjonalnych używanych w NKJP:
| Skrót | Objaśnienie |
| publ | publicystyczne |
| net_interakt | internetowe interaktywne (np. fora, blogi z komentarzami, listy dyskusyjne) |
| net_nieinterakt | internetowe nieinteraktywne (np. strony domowe, blogi bez komentarzy) |
| nd | naukowo-dydaktyczne |
| qmow | quasi-mówione |
| fakt | literatura faktu |
| urzed | urzędowe |
| lit | literatura |
| inf_por | informacyjno-poradnikowe |
| nklas | inne |
| lit_poezja | poezja |
| media | mówione-medialne |
| lit_proza | proza |
| konwers | mówione-konwersacyjne |
| lit_dramat | dramat |
Szeregi czasowe
Zasoby NKJP są bardzo zróżnicowane nie tylko ze względu na gatunek lub typu funkcjonalny tekstów, ale również z uwagi na czas ich powstania. Chociaż NKJP nie jest w zamierzeniu korpusem diachronicznym, w którym różne okresy czasu są reprezentowane równomiernie, to jednak dostępność informacji o dacie powstania/publikacji tekstu stwarza możliwości analizy frekwencji form językowych w zależności od czasu ich użycia. Analiza taka ukazuje, iż niektóre słowa, frazy, idiomy, nazwy własne i zwroty zyskują znacznie na popularności w krótkim czasie, odzwierciedlając tym samym nośność danego tematu w dyskursie publicznym.Wyszukiwarka PELCRA NKJP umożliwia wydobycie tego typu informacji o profilu diachronicznym słowa, lub frazy w bardzo prosty sposób. Po wpisaniu dowolnego zapytania w składni wyszukiwarki, należy kliknąć przycisk Czas. Po chwili, poniżej formularza wyszukiwania powinien się pojawić wykres szeregu czasowego, wraz z tabelą na podstawie której został on wygenerowany. Na przykład, aby sprawdzić popularność słów moherowy, lub moher we wszystkich odmianach w ostatnich 20 latach należy wpisać zapytanie moher**|moherowy** a następnie kliknąć przycisk Czas w formularzu zapytania

Jak widać na wygenerowanym w ten sposób diagramie, popularność tych wyrazów drastycznie wzrosła w latach 2005/2006:
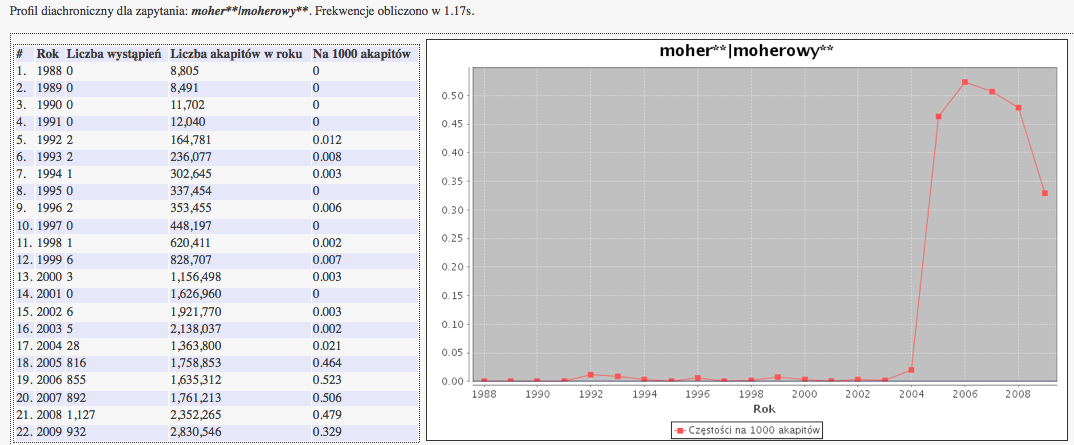
Odpowiednie zapytanie o wystąpienia tych wyrazów po 2005 roku ukazuje przyczynę tego wzrostu frekwencji. Moher i moherowy beret nabrały w tym czasie metonimicznego znaczenia i zaczęły funkcjonować jako pejoratywne, a często wręcz obraźliwe określenie pewnej grupy społecznej.
Pobieranie wyników w postaci arkuszy kalkulacyjnych
Widoczne na stronie wyniki wyszukiwania można pobrać z dodatkowymi metadanymi w postaci arkusza kalkulacyjnego MS Excel, po kliknięciu przycisku Excel. Dzięki temu, użytkownik może dla własnych potrzeb sortować i edytować wyniki wyszukiwania. Arkusze z wynikami mają rozszerzenie .xml i należy je otwierać bezpośrednio z programu MS Excel, lub Open Office (zalecane wersje to odpowiednio MS Office 2007 i OO 3.0). Zeszyt wyników zawiera dwa arkusze. W arkuszu Wyniki można znaleźć konkordancje z podstawowymi metadanymi: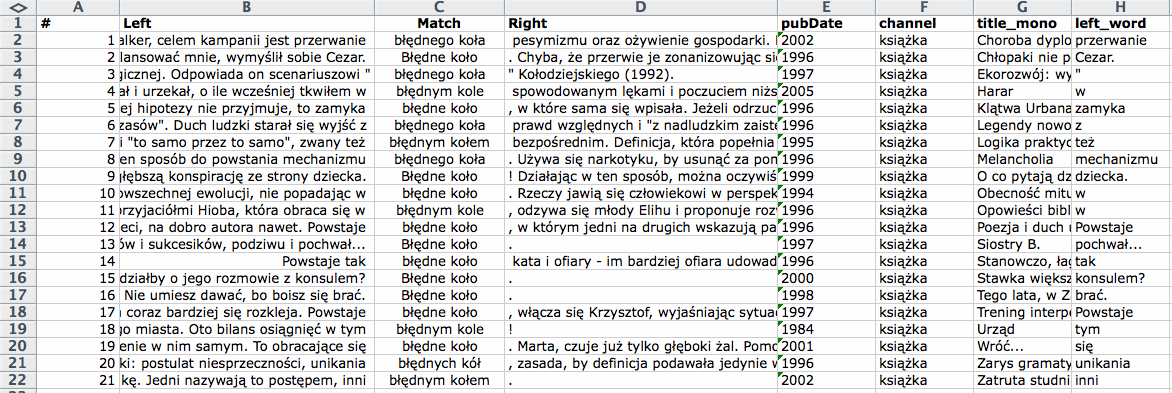
Warto zauważyć, że kolumna left_word zawiera słowo występujące bezpośrednio po lewej stronie dopasowania, dzięki czemu wyniki można sortować po lewym kontekście. W arkuszu Podsumowanie znajdują się informacje o zapytaniu i zbiorze wyników.
Wyszukiwanie kolokacji
Korpusy językowe zawierają cenne informacje o łączliwości frazeologicznej słów. Czasem typowe kolokacje danego wyrazu można wydobyć poprzez zwykłe posortowanie konkordancji po lewej lub prawej stronie, co umożliwia również wyszukiwarka PELCRA NKJP. Badanie kolokacji poprzez sortowanie konkordancji może jednak okazać się kłopotliwe w przypadku często występujących słów. Na przykład różne odmiany rzeczownika niebo występują prawie 18 000 razy w demonstracyjnej wersji korpusu NKJP. Ręczne przejrzenie wszystkich jego wystąpień w celu ustalenia najczęstszych kolokacji przymiotnikowych tworzonych z tym rzeczownikiem byłoby co najmniej niepraktyczne. Kolokator to moduł automatycznej ekstrakcji kolokacji zaimplementowany w wyszukiwarce PELCRA NKJP, który znacznie ułatwia to zadanie.Ekstrakcja kolokacji pojedynczych wyrazów - niebo**
Aby wyszukać lewostronne kolokacje przymiotnikowe rzeczownika niebo w różnych odmianach, należy najpierw sformułować odpowiednie zapytanie o ośrodek kolokacji, którym w tym wypadku jest wyraz niebo. W tym celu używając opisanej powyżej składni, wpisujemy zapytanie niebo** do pola tekstowego ko, tak jak to ukazano na ilustracji poniżej. Dwie gwiazdki na końcu wyrazu oznaczają, że chodzi nam o wszystkie odmiany tego rzeczownika.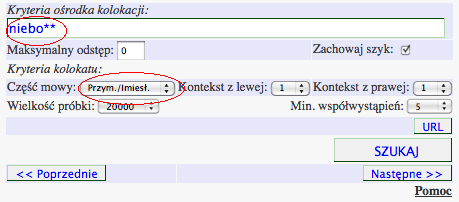
Kolejnym krokiem jest określenie kryteriów kolokacji. Ponieważ chcemy wyłuskać z korpusu kolokacje przymiotnikowe, z listy Części mowy wybieramy opcję Przym./Imiesł., która uwzględnia przymiotniki i imiesłowy przymiotnikowe. Opcje Kontekst z lewej oraz Kontekst z prawej określają liczbę sąsiadujących z zadanym ośrodkiem kolokacji wyrazów, które mają być rozpatrywane jako część potencjalnych kolokacji.
Ze względu na złożoność obliczeniową ekstrakcji kolokacji, nasza wyszukiwarka chwilowo jest w stanie jednorazowo w ciągu kilku sekund przeanalizować do 50 000 kontekstów wystąpień danego ośrodka kolokacji. Kolokacje wyrazów występujących w korpusie częściej niż 50 000 razy można wydobyć stopniowo, klikając przycisk Następne.
Po kliknięciu przycisku Szukaj należy odczekać kilka sekund (konteksty wystąpień ośrodka kolokacji są analizowane w tempie 3000/s.). Poniżej formularza zapytania powinna się ukazać tabela wyników, co ilustruje przedstawiony poniżej zrzut ekranu:
Kolokacje niebo** - bezpośredni odsyłacz

Na górze tabeli wyników podana jest kolejno ogólna liczba wystąpień ośrodka kolokacji w korpusie, liczba przenalizowanych kontekstów, oraz liczba potencjalnych kolokacji. Pierwsza kolumna tabeli wyników podaje liczbę porządkową kolokacji. W drugiej kolumnie wyświetlone są znormalizowane formy podstawowe kolokatów. Trzecia kolumna podaje konkretne kombinacje kolokacyjne dla wszystkich odmian formy podstawowej podanej w poprzedniej kolumnie, oraz liczebności poszczególnych kombinacji. Po kliknięciu na liczebność, w osobnym oknie wyświetlane są konkordancje danej kombinacji. Pozwala to zweryfikować wyniki grupowania odmian do formy podstawowej. W czwartej kolumnie ukazano ogólną liczebność wszystkich form, która jest sumą form wszystkich kombinacji. Ostatnia kolumna podaje wartość chi kwadrat, która określa istotność statystyczną danej kolokacji. Właśnie według tej wartości sortowane są potencjalne kolokacje. Sortowanie kolokacji według zwykłej liczebności współwystąpień słów obniża czytelność wyników, ze względu na dużą ilość częstych słów, które tworzą z zadanym wyrazem związki składniowe, a nie kolokacyjne.
Jak widać do typowych kolokacji rzeczownika niebo można zaliczyć takie frazy jak: gołe niebo, rozgwieżdżone niebo, bezchmurne niebo, siódme niebo, itd., co chyba pozostaje w zgodzie z intuicją leksykalną użytkowników polszczyzny. Ciekawe są także informacje o preferencjach frazeologicznych wyłaniających się z liczebności niektórych form, np. rozgwieżdżone/wygwieżdżone/gwieździste/gwiaździste niebo.
Warto pamiętać, że wyszukiwarka nie zawsze jest w stanie rozszerzyć zapytanie o formy pokrewne morfologicznie. Na przykład, jeżeli dla ośrodka kolokacji zdefiniowanego jako VAT** nie zwrócono żadnych wyników, to warto użyć zwykłego rozszerzenia ortograficznego, stosując zapytanie z jedną, a nie dwiema gwiazdkami, czyli VAT*.
Ekstrakcja złożonych kolokacji - dojść** do
Wyszukiwarka kolokacji umożliwia także badanie kolokacji wielowyrazowych ośrodków kolokacji. Na przykład, aby wyszukać kolokacje występujące z czasownikiem dojść i przyimkiem do, można sformułować następujące zapytanie:Kolokacje dojść** do - bezpośredni odsyłacz
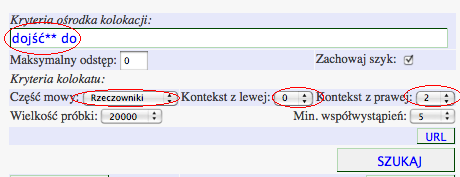
Kontekst kolokacyjny ustawiono w tym przypadku na 2 słowa z prawej strony dopasowania. Jak widać na poniższym zrzucie ekranu, najbardziej istotne statystycznie kolokacje rzeczownikowe zwrócone przez powyższe zapytanie to między innymi dojść do skutku/wniosku/porozumienia/przekonania.

Jak rozumieć wartość chi-kwadrat?
Potencjalne kolokacje są obecnie sortowane według wartości testu statystycznego chi-kwadrat, który dość precyzyjnie określa jeden z aspektów łączliwości frazeologicznej. W najbliższym czasie stopniowo będziemy dodawać implementacje innych metod ekstracji kolokacji.Podana w ostatniej kolumnie tabeli wyników wartość chi-kwadrat wyraża prawdopodobieństwo tego, że częstotliwość współwystępowania ośrodka kolokacji z danym wyrazem w korpusie nie jest przypadkowa. Dokładniej wyrażają to wartości prawdopodobieństwa przypisane do wartości chi kwadrat dla jednego stopnia swobody:
| Chi kwadrat | 2,706 | 3,841 | 5,024 | 6,635 | 10,828 |
| Istotność statystyczna | 0,90 | 0,95 | 0,975 | 0,99 | 0,999 |
Jeżeli więc wartość testu chi-kwadrat podana w tabeli wyników wynosi 10,828, to z matematycznego punktu widzenia istnieje tylko jedna szansa na tysiąc, że dane dwa wyrazy występują w zadanych kontekstach zupełnie przypadkowo. Innymi słowy, prawdopodobieństwo tego, że liczba współwystąpień wynika tylko i wyłącznie z ogólnej częstości występowania pojedynczych wyrazów wynosi 0,001.
W obecnej wersji wyszukiwarki wyświetlane są wyniki o liczebności współwystąpień >=5, oraz o wartości testu chi kwadrat >= 3,841. Oczywiście częstość współwystępowania wyrazów nie jest tylko i wyłącznie funkcją ich łączliwości frazeologicznej i dlatego niektórych z współwystąpień wyrazów z wysoką wartością chi kwadrat nie można uznać za związki frazeologiczne.
Dostęp programistyczny
Wyszukiwarka obsługuje zapytania programistyczne przez protokół HTTP. Uwaga, ze względu na liczne nadużycia wymagamy obecnie użycia klucza dostępu. Najlepiej to ilustruje skrypt napisany w języku Python (kod):
Skrypt ten wysyła zapytanie do serwera i otrzymuje wyniki konkordancji w prostym formacie XML:

Możliwe jest również automatyczne pobieranie wyników konkordancji we wspomnianym powyżej formacie MS Excel XML (adres serwletu to http://nkjp.uni.lodz.pl/NKJPSpanSearchExcelXML).
Na razie nie stosujemy dodatkowych ograniczeń w automatycznym dostępie HTTP, ale mogą się one pojawić w przypadku nadużyć. Należy pamiętać, iż wszelkie formy komercyjnego wykorzystania wyszukiwarki wymagają uzyskania licencji konsorcjum NKJP.
Wyszukiwarka dla danych mówionych
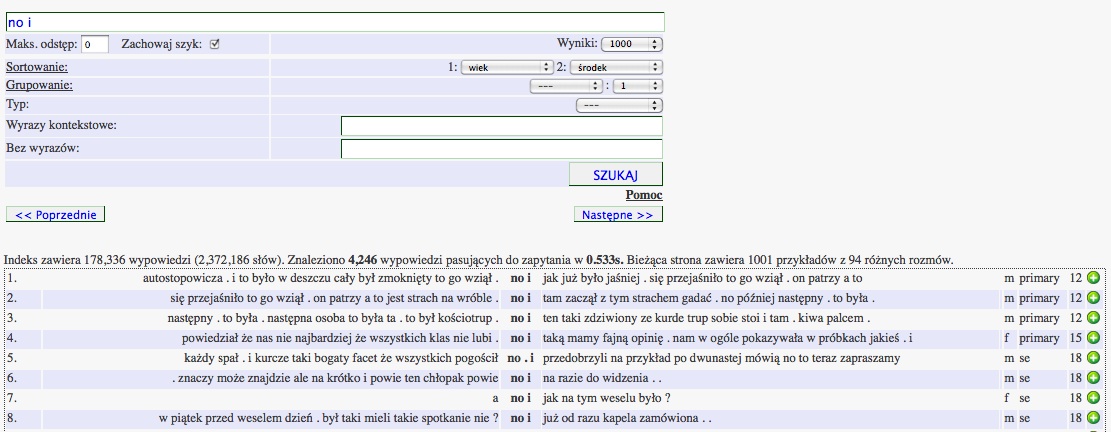
W puli danych NKJP znajduje się obecnie ponad 2 miliony słów języka mówionego zarówno medialnych jak też konwersacyjnych. Dane mówione-medialne to transkrypcje audycji telewizyjnych oraz radiowych. Mianem danych mówionych konwersacyjnych określamy transkrypcje nagrań rozmów dokonywanych specjalnie na potrzeby opracowania korpusu PELCRA oraz NKJP. Struktura danych mówionych wymagała opracowania specjalnego schematu anotacji, który umożliwia przyporządkowanie wypowiedzi do poszczególnych rozmówców. Większość rozmówców w korpusie jest opisana znacznikami określającymi wiek, wykształcenie, płeć oraz region Polski, w którym stosunkowo najdłużej mieszkali.Wszystkie dane mówione można przeszukiwać w głównej wyszukiwarce NKJP, po wybraniu odpowiednich opcji typu i stylu tekstów. Niemniej jednak, dzięki osobnej wyszukiwarce dla danych mówionych można wygodniej przeszukiwać, sortować i wyświetlać konwersacyjną część korpusu. Możliwe jest na przykład sortowanie konkordancji według wieku, wykształcenia lub też płci mówcy:
Cytowanie
Autorów powołujących się na wyszukiwarkę PELCRA NKJP prosimy o cytowanie następującej publikacji:Piotr Pęzik (2012) Wyszukiwarka PELCRA dla danych NKJP. Narodowy Korpus Języka Polskiego (Przepiórkowski A., Bańko M., Górski R., Lewandowska-Tomaszczyk B (red.). 2012. Wydawnictwo PWN . Do pobrania.
Autorów publikacji wykorzystujących wyszukiwarkę danych mówionych prosimy o cytowanie publikacji:
Piotr Pęzik (2012) Język mówiony w NKJP. Narodowy Korpus Języka Polskiego. Przepiórkowski A., Bańko M., Górski R., Lewandowska-Tomaszczyk B (red.). 2012. Wydawnictwo PWN . Do pobrania
Dalsze informacje
Uwagi dotyczące działania wyszukiwarki prosimy kierować na adres piotr.pezik@gmail.com.Informacje o błędach prosimy przesyłać przez ten formularz. Piotr Pęzik, 2008-2012